# import modules
import os
import numpy as np
import pandas as pd
# function to get cleaned data set
def get_cleaned_tweets_data(TYPE,LABEL,LANGUAGE,CLASS=''):
if CLASS == '':
file_t = 'clean-data/'+TYPE+'-'+LABEL+'-tweets'+CLASS+'-'+LANGUAGE+'.pkl'
elif CLASS == 'duplicates':
file_t = 'clean-data/'+TYPE+'-'+LABEL+'-tweets-'+CLASS+'-'+LANGUAGE+'.pkl'
elif CLASS == 'liwc':
file_t = 'clean-data-liwc/LIWC2015 Results ('+TYPE+'-'+LABEL+'-tweets-'+CLASS+'-'+LANGUAGE+'.csv).csv'
try:
if CLASS == '' or CLASS == 'duplicates':
df = pd.read_pickle(file_t)
elif CLASS == 'liwc':
df = pd.read_csv(file_t,index_col=0)
else:
print('No data ... Try again.')
df = None
return df
except:
print('ERROR: data file does not exist or input parameters are incorrect.')
print('Please download the necessary files first before loading the data.')
return None
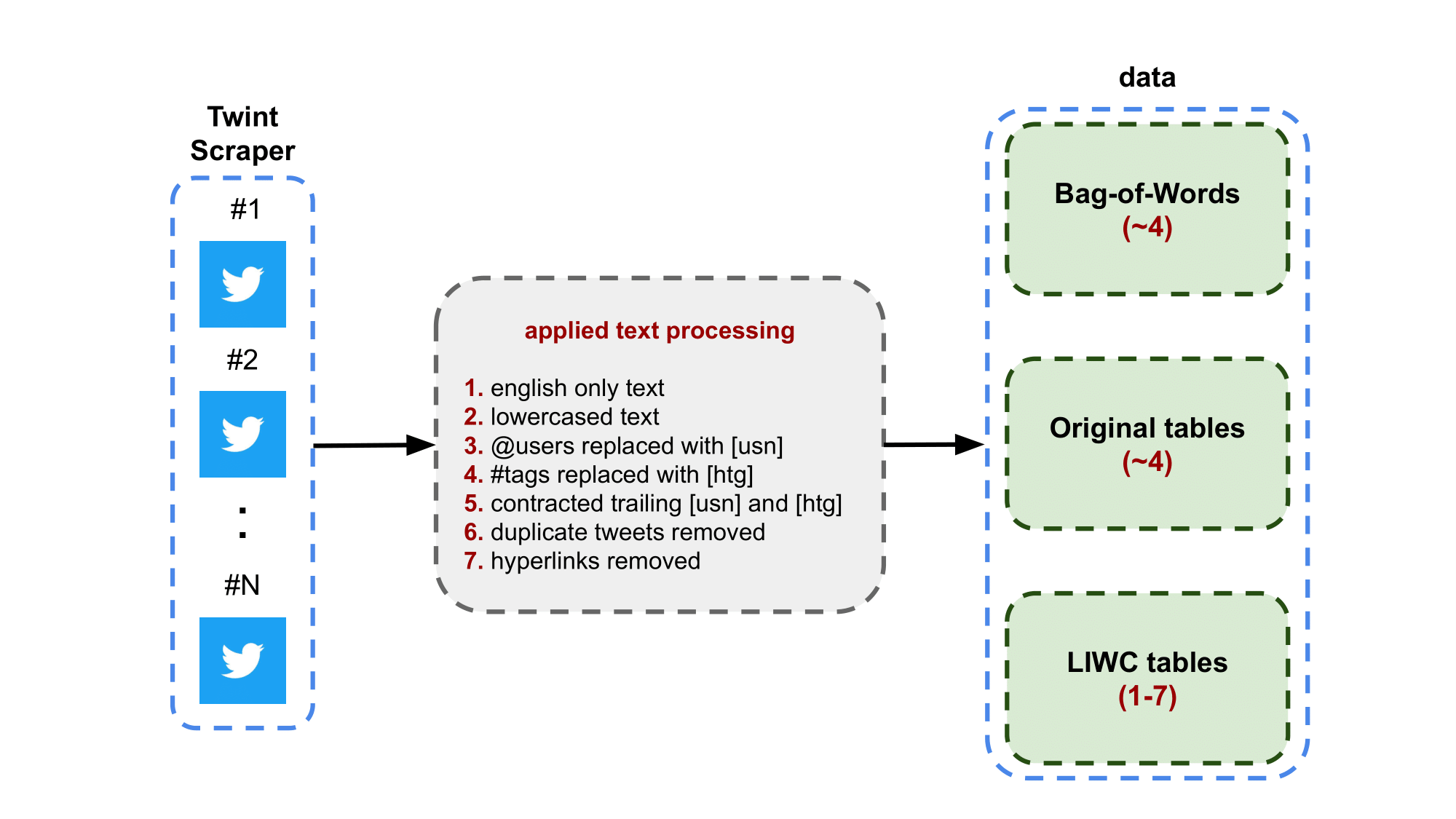
Scraper. The Tweets from Twitter are scraped using the Twint software. When scraping, a specific hashtag is entered as a query to request relevant tweets that contain that hashtag at a particular range of time. In this case, we have 94 hashtags scraped in the time-frame January 2013 to December 2020. Below is a diagram of the text processing of tweets. Twint's purpose is to scrape tweets without the use of a Twitter API to avoid most of the limits. What it does is using the search function on twitter and scrapes the search results accordingly.
Time Frame. The tweets was scraped in February 2021 using the time-frame January 2013 to December 2020. This means that any tweets - with a specified hashtag query - is scraped if it exists within that time-frame. Deleted tweets and users prior to February 2021 and private tweets may not exist since the scraper only takes available public tweets.
Tweet Text Processing. The diagram below illustrates the processing pipeline where the green boxes indicate separate data savepoints. The Bag-of-Words save point is where only the processed text is saved. The original tables savepoint is where the text and other tweet information is saved (e.g. favorite counts, reply counts, etc). The LIWC tables savepoint is where the text and LIWC metrics are saved. For all savepoints, texts was lowercased and the hyperlinks are removed. The scraper can take tweets in several languages but in our case, we only take the English texts. The username tag (e.g. @username) is anonymized by replacing it by the character "[usn]". For all trailing usernames, it was contracted into the "[usn]" character. The hashtags (e.g. #hashtag) in the tweet are not fully recognized within the vocabulary of LIWC. Therefore, the hashtags are replaced with the character "[htg]" and trailing hashtags are contracted similar to the usernames for the LIWC tables save point only. The processed text is entered into LIWC software and the results are organized into a table where the rows are labeled with unique tweets ids and the columns contain the text and the LIWC metrics (see the LIWC manual for the descriptions of the LIWC metrics/columns).
# create empty folders for downloaded data
try: os.mkdir('clean-data')
except: pass
try: os.mkdir('clean-data-bow')
except: pass
try: os.mkdir('clean-data-liwc')
except: pass
There are three data folders where each folder is associated with the type of data which are Bag-of-Words, Original table, or LIWC tables. All relevant files can be downloaded from Google Drive. The following lists the links to the files.
a. "combined" - contains compressed text data containing all of the tweets separated by subsets.
b. "group" - contains compressed text data grouped by hashtags and separated by subsets.
c. "temporal" - contains two subfolders:
i. "combined" - contains compressed text data separated into months and by subsets.
ii. "group" - contains compressed text data separated into months, by hashtag, and by subsets.Original Tables. This link directs you to a Google Drive folder where it contains ".pkl" files of the original tables separated by hashtags. Each file corresponds to a hashtag and it contains tweet data where the row labels are the tweet ids. A separate file containing duplicates is also in this folder.
LIWC Tables. This link directs you to a Google Drive folder where it contains ".csv" files of the LIWC tables separated by hashtags. Each file corresponds to a hashtag and it contains tweet data and the LIWC metrics. The row labels of the tables are the tweet ids
Step 1. Download necessary files.
Example: If you want to view the original containing the hashtag "climatechange", go the Google Drive folder **Original Tables** and download the ".pkl" file labeled "hashtags-climatechange-tweets-en.pkl".
Step 2. Move the file to the designated folder.
Example: From step 1, move the ".pkl" file labeled "hashtags-climatechange-tweets-en.pkl" to the folder labeled "clean-data".
Step 3. Use the scripts below to load the downloaded ".pkl" files.
# set type and language
TYPE = 'hashtags' # tweets with hashtags only
LANG = 'en' # There is only English language available
# set hashtag
example_hashtag = 'climatechange'
# original table
T = get_cleaned_tweets_data(TYPE,example_hashtag,LANG,CLASS='')
print(T.shape)
T[T['year'] == 2020][['text','favorite_count','retweet_count','reply_count','year','month']].head(2)
(6114590, 10)
| text | favorite_count | retweet_count | reply_count | year | month | |
|---|---|---|---|---|---|---|
| 1223032947948703744 | with a new decade comes new disruption: trends... | 22 | 6 | 1 | 2020 | 1 |
| 1223032800544092161 | [usn] how much #renewableenergy could [usn] ha... | 4 | 4 | 0 | 2020 | 1 |
# duplicates table
D = get_cleaned_tweets_data(TYPE,example_hashtag,LANG,CLASS='duplicates')
print(D.shape)
D.head(2)
(6114590, 2)
| text | duplicates | |
|---|---|---|
| 1747536 | [usn] these companies poison water without rem... | 20040 |
| 2331572 | by tackling #climatechange we’re harnessing th... | 8232 |
# LIWC table
L = get_cleaned_tweets_data(TYPE,example_hashtag,LANG,CLASS='liwc')
print(L.shape)
L[L['WC'] > 10][['B','Tone','Analytic','Authentic','Clout','WC','Dic']].head(2)
C:\Users\ajavq\anaconda3\lib\site-packages\numpy\lib\arraysetops.py:580: FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison mask |= (ar1 == a)
(6114590, 94)
| B | Tone | Analytic | Authentic | Clout | WC | Dic | |
|---|---|---|---|---|---|---|---|
| A | |||||||
| 296769562114936832 | [usn] tells [usn] [htg] will continue. calls f... | 25.77 | 97.53 | 43.37 | 90.87 | 15 | 46.67 |
| 296769401250791424 | jacoby: i raise the question for discussion: w... | 25.77 | 99.00 | 61.34 | 67.52 | 22 | 72.73 |